🐋 Execute DeepSeek R1 Dynamic 1.58-bit com Llama.cpp
Um grande agradecimento ao UnslothAI por seus incríveis esforços! Graças ao seu trabalho árduo, agora podemos executar o modelo completo DeepSeek-R1 com 671 bilhões de parâmetros em sua forma quantizada dinâmica de 1,58 bits (comprimido para apenas 131 GB) no Llama.cpp! E o melhor de tudo? Você não precisa mais se preocupar em precisar de GPUs ou servidores corporativos robustos — é possível executar este modelo em sua máquina pessoal (embora lentamente na maioria do hardware de consumo).
O único modelo verdadeiro DeepSeek-R1 no Ollama é a versão 671B disponível aqui: https://ollama.com/library/deepseek-r1:671b. Outras versões são modelos destilados.
Este guia foca em executar o modelo completo DeepSeek-R1 Dynamic 1.58-bit quantizado utilizando Llama.cpp integrado com Open WebUI. Para este tutorial, demonstraremos os passos com uma máquina M4 Max + 128GB RAM. Você pode adaptar as configurações para o seu próprio equipamento.
Passo 1: Instalar o Llama.cpp
Você pode escolher entre:
- Baixar os binários pré-compilados
- Ou compilar você mesmo: Siga as instruções aqui: Guia de Construção do Llama.cpp
Passo 2: Baixar o Modelo Fornecido pelo UnslothAI
Acesse a página do Unsloth no Hugging Face e baixe a versão quantizada dinâmica apropriada do DeepSeek-R1. Para este tutorial, usaremos a versão 1,58-bit (131GB), que é altamente otimizada e surpreendentemente funcional.
Conheça o seu "diretório de trabalho" — onde seu script Python ou sessão de terminal está sendo executado. Os arquivos do modelo serão baixados para uma subpasta desse diretório por padrão, então tenha certeza de conhecer o caminho! Por exemplo, se você executar o comando abaixo em /Users/yourname/Documents/projects, seu modelo baixado será salvo em /Users/yourname/Documents/projects/DeepSeek-R1-GGUF.
Para entender mais sobre o processo de desenvolvimento do UnslothAI e por que essas versões quantizadas dinâmicas são tão eficientes, confira o post no blog: UnslothAI DeepSeek R1 Dynamic Quantization.
Aqui está como baixar o modelo programaticamente:
# Instale as dependências do Hugging Face antes de executar isto:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF", # Especifique o repositório no Hugging Face
local_dir = "DeepSeek-R1-GGUF", # O modelo será baixado neste diretório
allow_patterns = ["*UD-IQ1_S*"], # Baixe apenas a versão 1,58-bit
)
Uma vez que o download estiver completo, você encontrará os arquivos do modelo em uma estrutura de diretórios como esta:
DeepSeek-R1-GGUF/
├── DeepSeek-R1-UD-IQ1_S/
│ ├── DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
│ ├── DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
🛠️ Atualize os caminhos nos próximos passos para corresponder à sua estrutura de diretórios específica. Por exemplo, se seu script estava em /Users/tim/Downloads, o caminho completo para o arquivo GGUF seria:
/Users/tim/Downloads/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf.
Passo 3: Certifique-se de que o Open WebUI está instalado e em execução
Se você ainda não tem o Open WebUI instalado, sem problemas! É uma configuração simples. Basta seguir a documentação do Open WebUI aqui. Depois de instalado, inicie o aplicativo — conectaremos isso em um passo posterior para interagir com o modelo DeepSeek-R1.
Passo 4: Servir o Modelo Usando Llama.cpp
Agora que o modelo foi baixado, o próximo passo é executá-lo usando o modo servidor do Llama.cpp. Antes de começar:
-
Localize o binário
llama-server. Se você compilou a partir do código-fonte (conforme descrito no Passo 1), o executávelllama-serverestará localizado emllama.cpp/build/bin. Navegue até este diretório usando o comandocd:cd [caminho-para-llama-cpp]/llama.cpp/build/binSubstitua
[caminho-para-llama-cpp]pelo local onde você clonou ou compilou o Llama.cpp. Por exemplo:cd ~/Documents/workspace/llama.cpp/build/bin -
Aponte para a pasta do seu modelo. Use o caminho completo para os arquivos GGUF baixados no Passo 2. Ao servir o modelo, especifique a primeira parte dos arquivos GGUF divididos (por exemplo,
DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf).
Aqui está o comando para iniciar o servidor:
./llama-server \
--model /[seu-diretorio]/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
🔑 Parâmetros para personalizar com base na sua máquina:
--model: Substitua/[your-directory]/pelo caminho onde os arquivos GGUF foram baixados na Etapa 2.--port: O padrão do servidor é8080, mas sinta-se à vontade para alterá-lo com base na disponibilidade de portas.--ctx-size: Determina o comprimento do contexto (número de tokens). Você pode aumentar se seu hardware permitir, mas tenha cuidado com o aumento no uso de RAM/VRAM.--n-gpu-layers: Defina o número de camadas que deseja transferir para sua GPU para uma inferência mais rápida. O número exato depende da capacidade de memória da sua GPU — consulte a tabela da Unsloth para recomendações específicas.
Por exemplo, se seu modelo foi baixado para /Users/tim/Documents/workspace, o comando seria assim:
./llama-server \
--model /Users/tim/Documents/workspace/DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
--port 10000 \
--ctx-size 1024 \
--n-gpu-layers 40
Assim que o servidor iniciar, ele hospedará um endpoint de API local compatível com OpenAI em:
http://127.0.0.1:10000
🖥️ Servidor Llama.cpp em execução
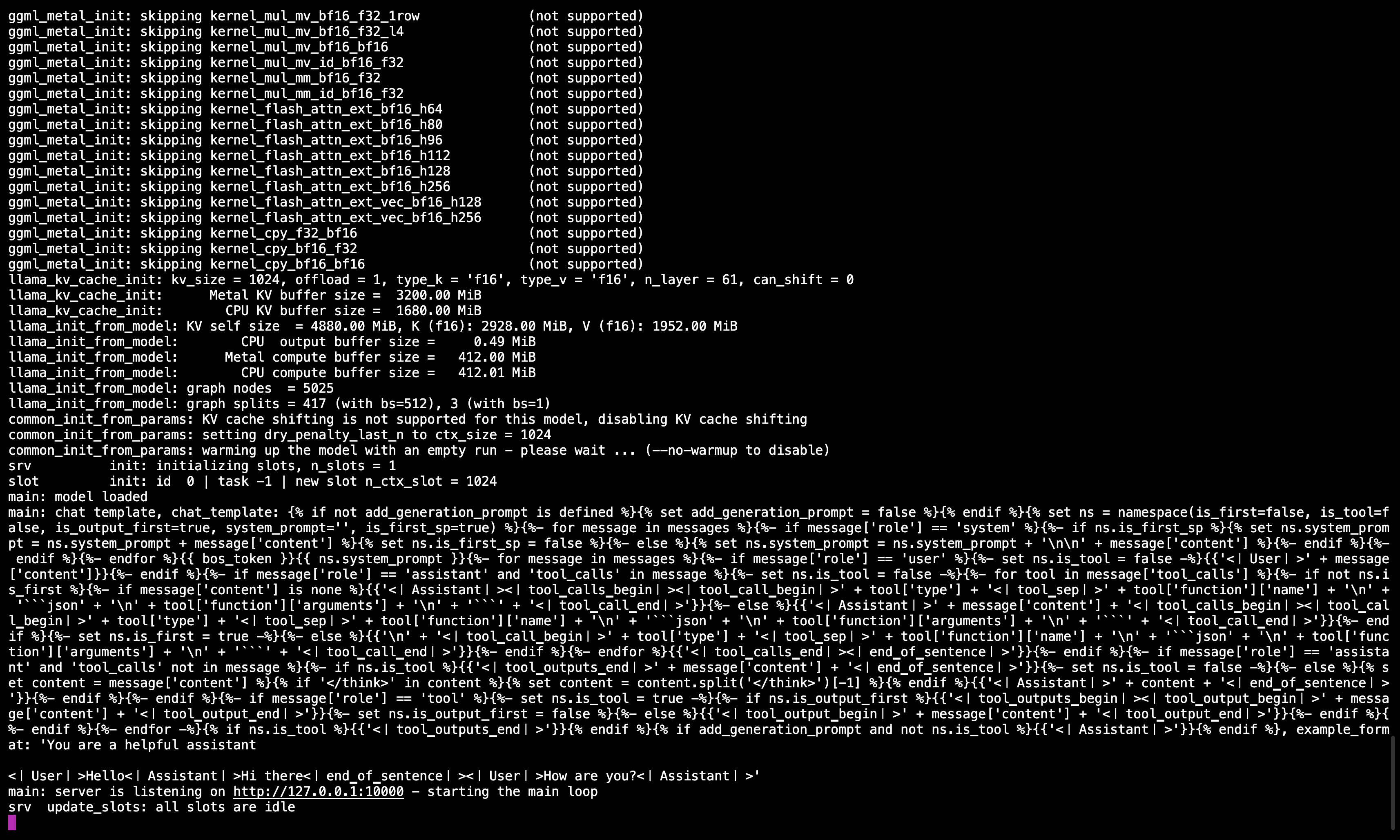
Após executar o comando, você deve ver uma mensagem confirmando que o servidor está ativo e ouvindo na porta 10000.
Certifique-se de manter esta sessão do terminal aberta, pois ela serve o modelo para todas as etapas subsequentes.
Etapa 5: Conectar Llama.cpp ao Open WebUI
- Vá para Admin Settings no Open WebUI.
- Acesse Connections > OpenAI Connections.
- Adicione os seguintes detalhes para a nova conexão:
- URL:
http://127.0.0.1:10000/v1(ouhttp://host.docker.internal:10000/v1ao executar o Open WebUI no Docker) - Chave de API:
none
- URL:
🖥️ Adicionando conexão no Open WebUI
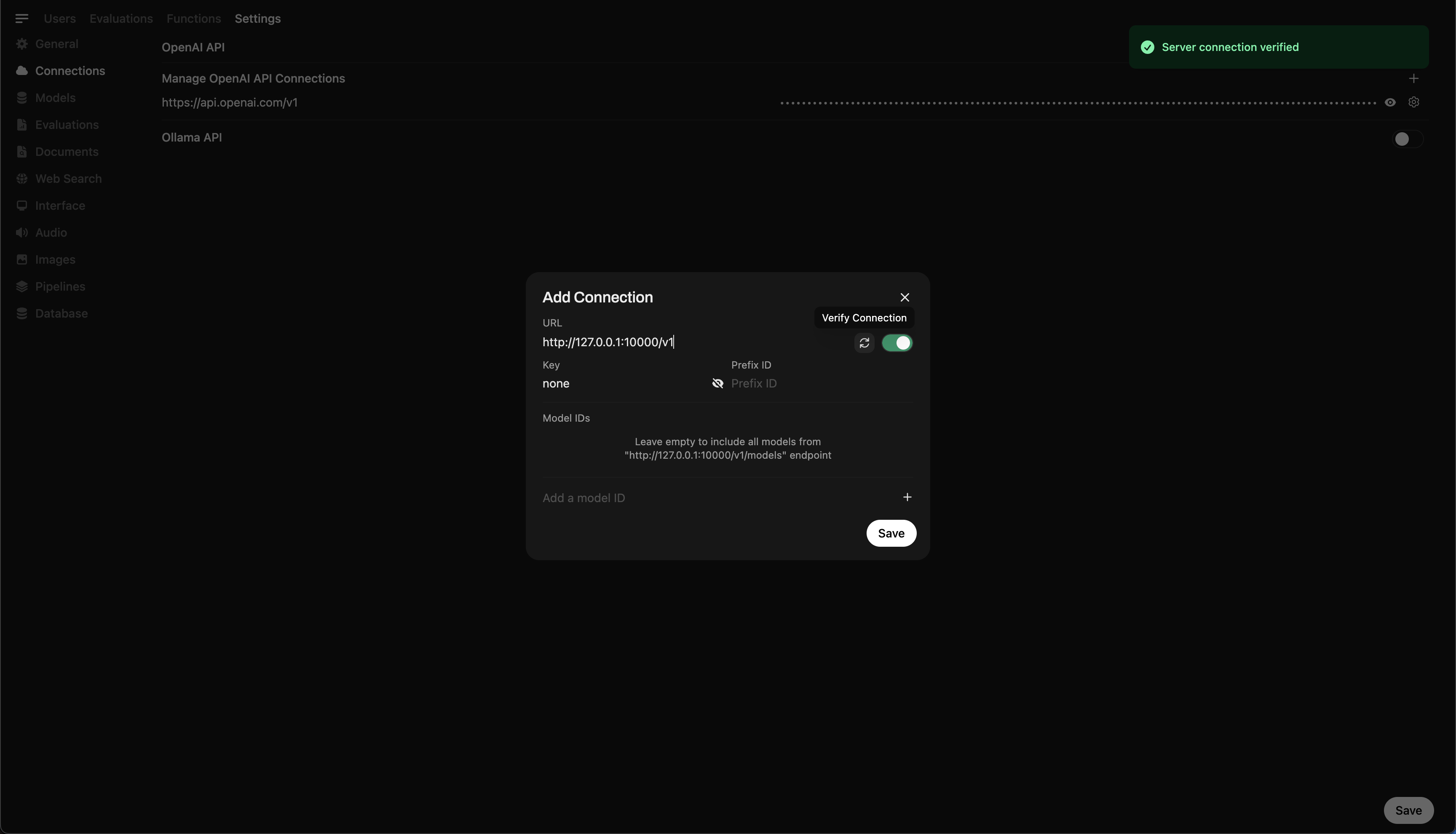
Após executar o comando, você deve ver uma mensagem confirmando que o servidor está ativo e ouvindo na porta 10000.
Depois de salvar a conexão, você pode começar a consultar DeepSeek-R1 diretamente do Open WebUI! 🎉
Exemplo: Gerando Respostas
Agora você pode usar a interface de chat do Open WebUI para interagir com o modelo DeepSeek-R1 Dynamic 1.58-bit.
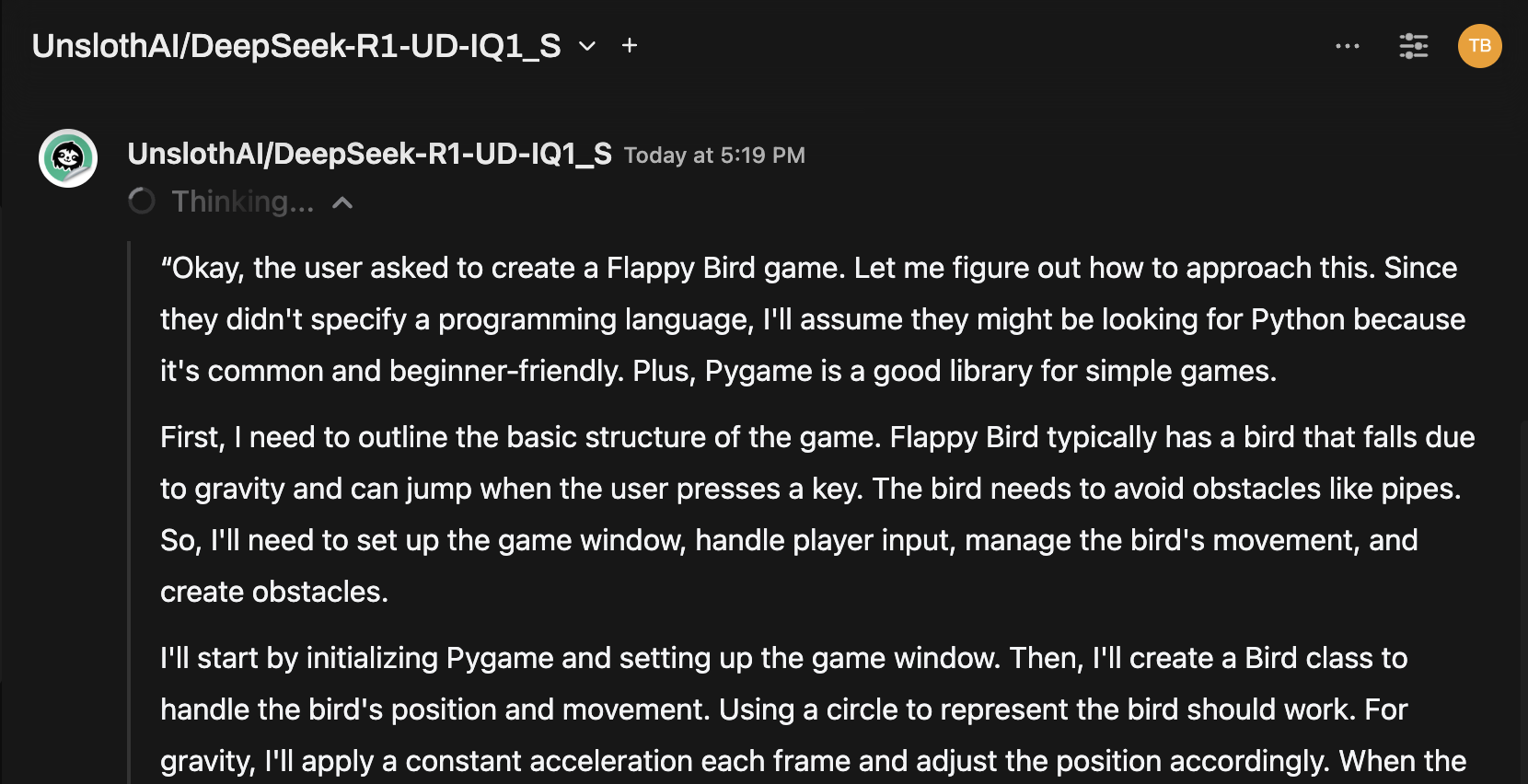
Notas e Considerações
-
Desempenho: Executar um modelo massivo de 131GB como o DeepSeek-R1 em hardware pessoal será lento. Mesmo com nosso M4 Max (128GB RAM), as velocidades de inferência foram modestas. Mas o fato de funcionar é um testemunho das otimizações da UnslothAI.
-
Requisitos de VRAM/Memória: Certifique-se de ter VRAM e RAM do sistema suficientes para um desempenho ótimo. Com GPUs de baixa capacidade ou configurações apenas com CPU, espere velocidades mais lentas (mas ainda é possível!).
Graças à UnslothAI e Llama.cpp, rodar um dos maiores modelos de raciocínio de código aberto, DeepSeek-R1 (versão 1.58-bit), está finalmente acessível para indivíduos. Embora seja desafiador executar tais modelos em hardware consumidor, a capacidade de fazê-lo sem uma infraestrutura computacional massiva é um marco tecnológico significativo.
⭐ Um grande agradecimento à comunidade por ampliar os limites da pesquisa em IA aberta.
Boas experimentações! 🚀